Michell Esmelin Matamoros Alvarado a, Mario Antonio Rodríguez Varela b, Cristian Samir Hernández González c y Jared Isaac Alfaro Funes c
a Estudiante Ingeniera en Sistemas en la UNAH
michell.matamoros@unah.hn
b Estudiante Ingeniera en Sistemas en la UNAH
antonio.varela@unah.hn
c Estudiante Ingeniera en Sistemas en la UNAH
hernandezcristian@unah.hn
d Estudiante Ingeniera en Sistemas en la UNAH
jared.alfaro@unah.hn
Resumen. La infraestructura de bases de datos es fundamental en una organización hoy en día, por ello; el crecimiento en el uso de bases de datos ha sido impresionante, los sistemas RDBMS dominan el área de base de datos, aunque en los últimos años hemos visto como las tecnologías no relaciones empiezan a tomar fuerza en este campo, entre ellas podemos mencionar base de datos no relacionales como Mongo DB. Pero muchas de las empresas siguen con el temor de invertir recursos en este tipo de tecnologías, por lo que siempre sigue el dominio de base de datos relacionales, cada empresa hace un análisis previo y conveniente de que tecnología de base de datos usar por lo que muchas invierten en lo que ya conocen y es fiable para ellos. Por medio de este articulo describiremos la infraestructura de base de datos, con diferentes opiniones e investigaciones realizadas con información actualizada en el campo hoy en día.
Abstract. The database infrastructure is essential in an organization today, therefore; the growth in the use of databases has been impressive, RDBMS systems dominate the database area, although in recent years we have seen how technologies do not begin to gain strength in this field, among them we can mention the database of non-relational data such as Mongo DB, but many of the companies are still afraid of investing resources in this type of technology, so the domain of data relational base always follows, each company makes a prior and convenient analysis of what technology database, so many invest in what they already know and trust. Through this article we will describe the database infrastructure, with different opinions and research carried out with updated information in the field today.
Palabras Claves. Estructura,escalable,SQL,NoSQL,sistemadistribuido,rol,arquitectura,seguridad,almacenamiento,datos.
Bases de datos
Historia de los sistemas de bases de datos
Marqués, A. M. (2011). Los predecesores de los sistemas de bases de datos fueron los sistemas de ficheros. Un sistema de ficheros está formado por un conjunto de ficheros de datos y los programas de aplicación que permiten a los usuarios finales trabajar sobre los mismos. No hay un momento concreto en el que los sistemas de ficheros hayan cesado y hayan dado comienzo los sistemas de bases de datos. De hecho, todavía existen sistemas de ficheros en uso. Se dice que los sistemas de bases de datos tienen sus raíces en el proyecto estadounidense de mandar al hombre a la luna en los años sesenta, el proyecto Apolo. En aquella época, no había ningún sistema que permitiera gestionar la inmensa cantidad de información que requería el proyecto. La primera empresa encargada del proyecto, NAA (North American Aviation), desarrolló una aplicación denominada GUAM (General Update Access Method) que estaba basada en el concepto de que varias piezas pequeñas se unen para formar una pieza más grande, y así sucesivamente hasta que el producto final está ensamblado. Esta estructura, que tiene la forma de un árbol, es lo que se denomina una estructura jerárquica. A mediados de los sesenta, IBM se unió a NAA para desarrollar GUAM en lo que después fue IMS (Information Management System). El motivo por el cual IBM restringió IMS al manejo de jerarquías de registros fue el de permitir el uso de dispositivos de almacenamiento serie, más exactamente las cintas magnéticas, ya que era un requisito del mercado por aquella época.
A mitad de los sesenta, General Electric desarrolló IDS (Integrated Data Store). Este trabajo fue dirigido por uno de los pioneros en los sistemas de bases de datos, Charles Bachmann. IDS era un nuevo tipo de sistema de bases de datos conocido como sistema de red, que produjo un gran efecto sobre los sistemas de información de aquella generación. El sistema de red se desarrolló, en parte, para satisfacer la necesidad de representar relaciones entre datos más complejas que las que se podían modelar con los sistemas jerárquicos y, en parte, para imponer un estándar de bases de datos. Para ayudar a establecer dicho estándar, el grupo CODASYL (Conference on Data Systems Languages), formado por representantes del gobierno de EEUU y representantes del mundo empresarial, fundaron un grupo denominado DBTG (Data Base Task Group), cuyo objetivo era definir unas especificaciones estándar que permitieran la creación de bases de datos y el manejo de los datos. El DBTG presento su informe final en 1971 y aunque éste no fue formalmente aceptado por ANSI (American National Standards Institute), muchos sistemas se desarrollaron siguiendo la propuesta del DBTG. Estos sistemas son los que se conocen como sistemas de red, sistemas CODASYL o DBTG.
Bases de datos y su estructura
La manipulación de los datos en la actualidad resulta ser indispensable, no solo en un carácter educativo si no también empresarial de manera que es de vital importancia entender la composición de dichas aglomeraciones de datos, para emprender el desarrollo tenemos que comprender que es un archivo según (Capacho, J. R., Bernal, W., & Nieto Bernal, W. (2017)) un archivo es una colección de registros que contiene n datos lógicamente relacionados.
Podemos destacar dos tipos de registro homogéneos y heterogéneos, El conjunto de registros es homogéneo cuando la estructura de registro del archivo es de longitud fija; y se dice que un conjunto de registros es heterogéneo cuando los registros son de longitud variable.
Por otra parte, a manera de complemento y de manera más concreta (Marqués, A. M.,2011) menciona que una base de datos es un conjunto de datos almacenados en memoria externa que están organizados mediante una estructura de datos. Cada base de datos ha sido diseñada para satisfacer los requisitos de información de una empresa u otro tipo de organización, como, por ejemplo, una universidad o un hospital.
Antes de existir las bases de datos se trabajaba con sistemas de ficheros. Los sistemas de ficheros surgieron al informatizar el manejo de los archivadores manuales para proporcionar un acceso más eficiente a los datos almacenados en los mismos. Un sistema de ficheros sigue un modelo descentralizado, en el que cada departamento de la empresa almacena y gestiona sus propios datos mediante una serie de programas de aplicación escritos especialmente para él. Estos programas son totalmente independientes entre un departamento y otro, y se utilizan para introducir datos, mantener los ficheros y generar los informes que cada departamento necesita. Es importante destacar que, en los sistemas de ficheros, tanto la estructura física de los ficheros de datos como de sus registros, están definidas dentro de los programas de aplicación.
Cuando en una empresa se trabaja con un sistema de ficheros, los departamentos no comparten información ni aplicaciones, por lo que los datos comunes deben estar duplicados en cada uno de ellos. Esto puede originar inconsistencias en los datos. Se produce una inconsistencia cuando copias de los mismos datos no coinciden: dos copias del domicilio de un cliente pueden no coincidir si sólo uno de los departamentos que lo almacenan ha sido informado de que el domicilio ha cambiado.
Otro inconveniente que plantean los sistemas de ficheros es que cuando los datos se separan en distintos ficheros, es más complicado acceder a ellos, ya que el programador de aplicaciones debe sincronizar el procesamiento de los distintos ficheros implicados para garantizar que se extraen los datos correctos. Además, ya que la estructura física de los datos se encuentra especificada en los programas de aplicación, cualquier cambio en dicha estructura es difícil de realizar. El programador debe identificar todos los programas afectados por el cambio, modificarlos y volverlos a probar, lo que cuesta mucho tiempo y está sujeto a que se produzcan errores. A este problema, tan característico de los sistemas de ficheros, se le denomina también falta de independencia de datos lógica-física.
Una base de datos se puede percibir como un gran almacén de datos que se define y se crea una sola vez, y que se utiliza al mismo tiempo por distintos usuarios. En una base de datos todos los datos se integran con una mínima cantidad de duplicidad. De este modo, la base de datos no pertenece a un solo departamento, sino que se comparte por toda la organización. Además, la base de datos no sólo contiene los datos de la organización, también almacena una descripción de dichos datos. Esta descripción es lo que se denomina metadatos, se almacena en el diccionario de datos o catálogo y es lo que permite que exista independencia de datos lógica-física.
Las bases de datos en una percepción más coloquial, se distingue como una estructura definida de manera que cumple con ciertos criterios que demanda el ámbito para el cual es desarrollada, las bases de datos en la actualidad pueden ser modificadas en el sentido que tengan versatilidad(escalable) a manera de adaptarse a la constante evolución de mayoría de las áreas de aplicación, en ese sentido no solo basta mencionar que las bases de datos son una aglomeración de los mismos, ya que en la actualidad se busca almacenar la mayor cantidad de información de manera que no solo por el hecho de estar almacenada tiene un sentido, en sí misma ya que necesita ser procesada.
Sistemas de gestión de bases de datos
(Marqués, A. M. (2011)) Un sistema de gestión de la base de datos (SGBD) es una aplicación que permite a los usuarios definir, crear y mantener la base de datos, además de proporcionar acceso controlado a la misma.
Dentro de los criterios de las bases de datos podemos mencionar que existen bases de datos de dos tipos, la primera de ellas serían las bases de datos relacionales denominadas(SQL), podemos mencionar ejemplos como lo son SQL Server perteneciente a la empresa Microsoft, Oracle SQL que pertenece a la empresa Oracle, estas alternativas de bases de datos SQL son herramientas que necesitan de licencia para poder usarse en un ambiente corporativo, también tenemos alternativas denominas Open Sours como es el caso de PostgreSQL, estos son sistemas de gestión de bases de datos relacionadas, en parte contrapuesta tenemos las bases de datos no relacionales, denominadas bases de datos NoSQL dentro de las cuales podemos mencionar MongoDB, Hadoop o también CouchDB entre otras, la diferencia una de la otra podríamos mencionar como punto toral por parte de las bases de datos NoSQL la no existencia de un identificador que se pueda utilizar para relacionar los datos.
Castro Romero, A., González Sanabria, J. S., & Callejas Cuervo, M. (2012, 12 diciembre). NoSQL hace referencia al conjunto de tecnologías en bases de datos que buscan alternativas al sistema de bases de datos relacional, en un contexto donde priman la velocidad, el manejo de grandes volúmenes de datos y la posibilidad de tener un sistema distribuido.
Es importante mencionar dentro de las herramientas de gestión de bases de datos la existencia de Sistema operativo (OS) especializados como los son Windows Server o también Ubuntu Server lo cual sería la versión de paga y la versión Open Sours, esto es importante de mencionar a manera de introducción a lo que posteriormente se estará desarrollando.
En la página web oficial de Microsoft se describe L. (2018, 31 mayo) Windows Server es un grupo de sistemas operativos diseñados por Microsoft que admite la administración de nivel empresarial, el almacenamiento de datos, las aplicaciones y las comunicaciones. Las versiones anteriores de Windows Server se han centrado en la estabilidad, la seguridad, las redes y varias mejoras en el sistema de archivos. Otras mejoras también han incluido mejoras en las tecnologías de implementación, así como un mayor soporte de hardware. Microsoft también ha creado SKU especializadas de Windows Server que se centran en los mercados doméstico y de pequeñas empresas. Windows Server 2012 R2 es la última versión de Windows Server y se centra en la informática en la nube.
Mientas del Sistema Operativo promocionado por Ubuntu podemos mencionar su rendimiento y versatilidad, donde mencionada aspectos de escalabilidad horizontal mediante este sistema operativo, (Server – for scale out workloads. (2020).) Ubuntu Server aporta escalabilidad económica y técnica a su centro de datos, público o privado. Ya sea que desee implementar una nube de OpenStack, un clúster de Kubernetes o una granja de servidores de representación de 50.000 nodos, Ubuntu Server ofrece el mejor rendimiento de escalado horizontal de valor disponible, dentro de las novedades que menciona dicha página web resulta interesante la mención de funcionamiento en todas las arquitecturas principales: x86-64, ARM v7, ARM64, POWER8, POWER9, IBM s390x (LinuxONE) e introduce soporte inicial para RISC-V, Compatibilidad con el modelado de esquemas OVS en Netplan para una configuración avanzada de la pila de redes, Imágenes en la nube de Ubuntu Pro para AWS y Azure, que incluyen endurecimiento, certificación, livepatch del kerne como también la compatibilidad con el último servicio de metadatos de instancias (IMDSv2) en Amazon Web Services (AWS).
Actualmente la última versión de Ubuntu server se encuentra en su versión 20.04 LTS esto nos da por entendido que dentro de las principales prioridades de los desarrolladores de dicho sistema es estar a la vanguardia y en el cumplimiento de los más altos estándares de confort para sus usuarios, esto y su costo, resultan ser uno de los principales criterios de adopción por parte de las empresas por este sistema ante otros que se necesita de una licencia para ser utilizados.
Ventajas e inconvenientes de las bases de datos
Es importante mencionar los inconvenientes que presiden la utilización de bases de datos como tal, en este sentido nos centraremos en la concepción de bases de datos relacionales como tal, dentro de los márgenes de ventajas y complicaciones el escritor (Gómez, J. M. P., & PIÑEIRO GOMEZ, J. M. (2014).) menciona que, dentro de las ventajas e inconvenientes de las bases de datos, La sustitución de un conjunto de ficheros por una base de datos proporciona las siguientes ventajas:
Independencia de los datos respecto a los tratamientos y viceversa: esto quiere decir que un cambio en los tratamientos o programas no va a con llevar una modificación en la base de datos, un nuevo diseño de la ma. Por otra parte, la realización de modificaciones sobre la base de datos, como inclusiones o modificaciones de informaciones o cambios en la estructura física de los datos, no va a implicar una modificación en los programas que acceden los datos de la base de datos.
Consistencia de los datos: Eliminando o controlando las redundancias de datos se reduce el riesgo de que haya inconsistencias. Si la redundancia es mínima y está controlada por el sistema, como ocurre en las bases de datos, el propio sistema se encargará de garantizar que las copias se mantienen consistentes.
Compartición de datos: En los sistemas de ficheros, estos pertenecen a las personas o departamentos que hacen uso de ellos. Cuando se trabaja con una base de datos, esta pertenece a la empresa puede ser compartida por todos los usuarios que tienen autorización para ello.
Mayor valor informativo: En la base de datos se almacenan los datos junto con las interrelaciones existentes entre ellos, por lo que el valor informativo del conjunto (de la base de datos) es mayor que la suma del valor informativo de los elementos individuales.
Mejora en la accesibilidad a los datos: Los sistemas gestores de bases de datos incluyen lenguajes de consulta que permiten a los usuarios con pocos conocimientos informáticos realizar consultas sobre los datos sin necesidad de escribir programas para tal fin.
Mejora de la integridad de los datos: La integridad de la base de datos, que se refiere a la consistencia y validez de los datos almacenados, se expresa mediante determinadas condiciones o restricciones que se deben cumplir. Pues bien, el; sistema gestor de la base de datos se encarga de asegurar que estas condiciones se cumplan. Esto se debe a que en una base de datos no solo se almacenan los datos propiamente dichos sino también la semántica de los mismos.
Control de la concurrencia: En algunos sistemas de ficheros, si hay varios usuarios que acceden simultáneamente a un mismo fichero, es posible que se pierda información o que afecte a la integridad de los datos. Sin embargo, los sistemas gestores de bases de datos gestionan el acceso concurrente a la base de datos y permiten que no ocurra este tipo de problemas.
Reducción del espacio de almacenamiento: La desaparición o disminución de la redundancia en las bases de datos conlleva una ocupación menor de memoria secundaria.
El trabajo con bases de datos se ha generalizado desde hace ya varias décadas debido a sus ventajas frente al trabajo con ficheros, No obstante, los sistemas de bases de datos también presentan algunos Inconvenientes que se van a indicar a continuación.
Instalación costosa a implantación de un sistema de bases de datos puede implicar elevados costes en adquisición de hardware y software, entre los cuales es de destacar el coste de adquisición y mantenimiento de Sistema gestor de la base de datos 1SGBD.
Personal especializado: Va a ser necesaria la contratación de personal especializado que se encargue del diseño u administración de la base de datos.
Falta de rentabilidad a corto plazo: La implantación de un sistema de base de datos, Por los costes que conlleva tanto en personal como en equipos y Por el tiempo que tarda en estar operativo, no resulta rentable a corto plazo, aunque si lo sea a medio y largo plazo.
Baja estandarización, Aunque existen estándares y su uso es muy frecuente, estos son bastante abiertos y hay importantes diferencias entre Sistemas gestores.
Base de datos en la nube
En base de datos mencionamos un área vital, en cuanto al tema de computación en la nube, tenemos las bases alojadas en la nube, una base de datos en la nube es una serie de contenido estructurado o no, que reside en una plataforma de infraestructura en la nube, estas a su vez pueden ser privadas, públicas o hibridas.
¿Qué ventajas tendríamos con una base de datos en la nube?
Haciendo énfasis en (Wendy A. Neu,Vlad Vlasceanu, Andy Oram y Sam Alapati,Septiembre,2019), tenemos algunas ventajas que nos benefician al usar servicios en la nube como ser:
- Ahorro en infraestructura de hardware, se ahorra el gasto de tener equipo físico, además de que ahorramos espacio en el local de la empresa.
- Mayor eficiencia y seguridad.
- Ofrecen diferentes ubicaciones de los servidores para una mayor satisfacción de acuerdo a nuestra ubicación.
- La nube nos proporciona mejores maneras de estabilidad, tolerancia a fallas y balances de carga.
- Los proveedores de servicios de servicios nos brindan distintas herramientas que nos ahorran el trabajo de creación.
- Contamos con un respaldo fijo de nuestras bases de datos.
Dadas las ventajas anteriores podemos ver que todo es muy beneficioso, pero existen una desventaja, el costo de estos servicios no es de bajo costo, pero nos hace competir a nivel de tecnología a nivel empresarial, ya que nos facilitan comprar otras herramientas.
Hablaremos de los tipos de bases de datos alojadas en la nube y que diferencias existen entre ellas, existen 2 categorías:
Bases de datos autoadministradas: (Wendy A. Neu,Vlad Vlasceanu, Andy Oram y Sam Alapati,Septiembre,2019), como su palabra lo dice, estas son administradas por el área de TI de la empresa que se encarga de todos los mantenimientos en la base de datos y herramientas, el proveedor solo nos brindara el hipervisor para la ejecución de su VM(Máquina Virtual).
Base de datos administradas: (Wendy A. Neu,Vlad Vlasceanu, Andy Oram y Sam Alapati,Septiembre,2019), en este caso la el mantenimiento y seguridad de la base de datos es dada por el proveedor el cual es el encargado de velar por actualizar y mantener segura la base de datos proveída .
¿Qué opción sería la más indicada para mi empresa?
Pues la opción que mejor le convenga, si su empresa quiere tener un control más directo, escogeremos la base de datos autoadministrada, pues supervisaremos la seguridad por nuestra cuenta y bajo un control de acuerdo a las reglas de la compañía, pero si no quiere hacer todo ese trabajo pues podemos usar la administrada que nos ahorrara el tiempo de actualizaciones y seguridad hasta cierto punto, pues no todo es totalmente administrado por el proveedor de servicios en la nube.
Las bases de datos administradas se subdividen a su vez en dos categorías las bases de datos tradicionales y las nativas de la nube, la diferencia es mínima recordemos que un proveedor de servicios en la nube no nos va ofrecer bases de datos tradicionales como ser ORACLE, PostgreSQL, MySQL o SQL server lo que podemos es migrar estas bases de datos a la nube, en cuento a las nativas son bases de datos proporcionadas por el proveedor de servicios en la nube, tenemos por ejemplo la base de datos brindada por Amazon que es Amazon Aurora ,una base de datos nativa o propia de los proveedores de Amazon, otro ejemplo es Azure Cosmos DB que es una base de datos nativa propia de Azure servicio en la nube de Microsoft, también y no menos importante tenemos el servicios brindado por Google ,con su bases de datos nativa Cloud Spanner todas estas están diseñadas para grandes exigencias por lo que la opción que tomemos como compañía dependerá de la preferencias y sobre todo los beneficios que nos brinde cada una.
Según(Wendy A. Neu,Vlad Vlasceanu, Andy Oram y Sam Alapati,Septiembre,2019),”Actualmente la mayoría de bases de datos en el mercado laboral son administradas” lo cual permite a las empresas evitar carga de trabajo para un DBA en cuestión de mantenimiento y actualizaciones, claro está; qué ,depende de los requerimientos que la empresa tenga ,recordemos que si tenemos una base de datos administrada no necesariamente tiene que ser nativa, se da el caso que queramos migrar nuestra base de datos con una base de datos tradicional ,lo cual dependerá de nosotros elegir el proveedor de servicios correcto, por ejemplo estos son algunos proveedores de servicio si nuestra empresa utiliza servicios en Microsoft tenemos la opción de servidor Azure la cual incluye o trabaja con base de datos tradicional SQL Server , en caso de que prefiramos los servicios de Amazon ,MariaDB, MySQL, Oracle, PostgreSQL y SQL Server en cuanto a los servicios de bases tradicionales están serían las opciones ,pero no solo existen servicios en cuanto a bases relacionales .
De igual manera en la nube podemos tener nuestros almacenes de datos destinados a la inteligencia de negocios, lo que nos permitirá hacer consultas más precisas de los datos almacenados en nuestra base de datos, conoceremos algunos servicios de almacenes de datos que bridan las diferentes compañías de servicios en la nube, una de las ventajas de los almacenes de datos es que la extracción rápida de datos lo que permite utilizar estas informaciones en aplicaciones destinadas a Big Data.
Algunos ejemplos de servicios de Almacenes de datos brindados en la nube son:
- Amazon Redshift.
- Google Big Query.
- Azure SQL Data Warehouse.
En el caso de almacenamiento de bases de datos no relaciones podemos encontrar de diferentes tipos las cuales podemos subir a la nube o que estas sean proveídas por medio de nuestro proveedor de servicios, entre los tipos de bases de datos no relacionales se encuentran:
- Clave-Valor (almacenamiento y recuperación de valores sin soporte).
- Documentos (Almacenan documentos como documentos JSON).
- Gráficos (Almacenan relaciones de objetos, para la ejecución de algoritmos).
- Búsquedas (Por medio de estas se optimizan búsquedas de documentos con palabras especificas).
- Series Temporales (Útiles para llevar un seguimiento de eventos).
- Libros Mayores (Registran actividades financieras de la empresa).
Mencionaremos algunos de los servicios nativos que ofrecen algunos proveedores de servicios actualmente, por ejemplo, Amazon ofrece Simple Storage Service (Amazon S3), Google cuenta con Google Cloud Storage y Microsoft Azure Blob Storage todos estos son servicios que podemos utilizar para almacenar base de datos no relacionales.
Todo lo descrito anteriormente es en cuanto al uso de la nube para el uso de las bases de datos, pero veremos cómo influye el rol de un DBA al usar las diferentes bases de datos ya mencionadas.
Rol de un DBA
En el campo de ingeniería en sistemas escuchamos muy seguido el termino DBA, pero al adentrarnos más en área de base de datos vemos que es un término muy complejo y nos hace hacernos preguntas como que es un DBA, que hace o porque son necesarios.
Toda organización hoy en día hace el uso de datos y muchas de ellas usan un sistema de administración de base de datos, más conocido como DBMS, al hacer uso de un DBMS es necesario un grupo encargado de la administración de la base de datos para asegurar el correcto uso e implementación de la base de datos. Además, con el incremento de los datos y la necesidad de organizar los datos efectivamente las empresas se ven obligadas a utilizar un DBMS para agregar valor a las necesidades del negocio. Aunque la disciplina de la administración de la base de datos no es muy comprendida ni es practicada en una forma coherente por las empresas de hoy en día.
Un DBA debe ser capaz de desarrollar varias tareas para asegurar que los datos y las bases de datos de una organización sean útiles, usables, disponibles y correctos.
Estas tareas incluyen diseño, modificaciones y monitoreo del rendimiento, asegurar la disponibilidad, seguridad, backup y recuperación, asegurar la integridad de los datos y cualquier intervención con la base de datos de la empresa. (Craig S. Mullins, 2013)
Diseño de la base de datos
Muchas personas hacen referencia que un DBA solo se encarga del diseño de la base de datos, cuando el diseño en si es una de las habilidades más importantes que un DBA debe tener. Para crear y diseñar apropiadamente base de datos relacionales un DBA debe entender las mejores prácticas del diseño relacional, al haber varias plataformas de DBMS, necesita comprender la teoría relacional y como implementarla al RDBMS. La habilidad de crear e interpretar diagramas de entidad-relación es esencial para el diseño de la base de datos relacional.
El DBA debe tener la habilidad de transformar un modelo de datos lógicos a una implementación de la base de datos físicamente. El DBA debe asegurarse que el diseño y la implementación de la base de datos sean útiles para los requerimientos de las aplicaciones y aún más importante para las necesidades de los clientes que la van a usar.
Un mal diseño de la base de datos puede traer resultados catastróficos al DBA, una base de datos con bajo rendimiento por su diseño, una base de datos que no cumpla con los requerimientos del cliente y con datos potencialmente imprecisos.
Modificaciones y monitoreo del rendimiento
Este es el segundo rol más asociado con un DBA. ¿Pero nos preguntamos a que se refiere con el rendimiento de la base de datos?, para entender vamos a hacer relación a cómo funcionan los mercados con el concepto de oferta y demanda, en nuestro caso un usuario demanda información de la base de datos. El DBMS provee información a los usuarios demandando información. La velocidad en que el DBMS provee la información a los usuarios es conocido por rendimiento de la base de datos. Pero hay factores que considerar en la velocidad de las bases de datos:
- Carga de trabajo: es una combinación de transacciones, trabajos por lotes, consultas y almacenamiento de datos.
- Procesamiento: se define por la capacidad en general de la computadora y el software para procesar todas las consultas a la base de datos.
- Recursos: se define por el hardware y software a la disposición del sistema.
- Optimización: se refiere a las mejores prácticas para la creación y realización de las consultas a la base de datos.
- Contienda: se refiere a la condición en la cual dos o más componentes de la carga de trabajo están tratando de utilizar un solo recurso ocasionando un conflicto entre ambos.
Cabe recalcar que con solo estos factores no solo son suficientes para el alcance del monitoreo ya que un DBA no solo necesita ser experto en el DBMS sino en todas las aplicaciones, sistemas e infraestructura con la cual el DBMS interactúa. El DBA se apoya en el uso de software automatizado y scripts para este rol.
Asegurar la disponibilidad
La base de datos contiene varios componentes que considerar para mantenerla disponible es por esto por lo que se considera un proceso multifacético. El primer componente de la disponibilidad es mantener el DBMS corriendo.
La base de datos debe estar diseñada para que pueda ser mantenida con el mínimo de interrupciones, para que los datos contenidos estén disponibles cuando las aplicaciones o clientes lo requieran. Al implementarlo así ayuda a las aplicaciones a minimizar los conflictos cuando el acceso concurrido sea necesario.
En la actualidad con tecnologías como la nube empresas están ahorrándose muchos costos de operaciones al tener modelos como IasS (Infraestructura como servicio), PaaS (Plataforma como servicio) o SaaS (Software como servicio). Una organización al implementar estos modelos se ahorra muchos costos ya que con estos modelos proveedores de la nube (Azure, AWS, Google Cloud, etc.) manejan todo el hardware proveyendo a empresas garantía, seguridad, escalabilidad entre otras ventajas solo con un modelo de pago por uso del servicio.
Pero aun con la existencia de la nube empresas siguen invirtiendo en una infraestructura donde ellos manejan el hardware y redundancia de sus sistemas utilizando UPS, Generadores, Enlaces directos de redes con un failover disponible en caso de cualquier disrupción de los servicios en su ubicación.
Al manejar hardware propio una empresa puede tener opciones para mantener su disponibilidad de la base de datos. El DBA debe asegurarse de mantener estos procesos bien aplicados ya que el será la primera persona al cual el cliente acudirá en caso de una disrupción de servicios. En estas opciones tenemos: clustering, log shipping, replicación de la base de datos, reflejar la base de datos (Database mirroring). (Thomas LaRock, 2010)
- Clustering: esta es una de las opciones más costosas, consiste básicamente en tener varios servidores físicos, se crea un servidor primario o nodo. Luego se agregan nodos secundarios al nodo primario donde cada nodo se define dentro del mismo grupo de recursos. En la red privada aparecerá solamente como un servidor, pero realmente está formado de múltiples instancias.

- Log Shipping: es otra opción para la disponibilidad de la base de datos, donde permite mantener los datos en dos o mas lugares a la misma vez. La idea es simple primero se crea un backup de el log de transacciones y ese backup se copia a otro servidor y así sucesivamente y de esa forma se podrá mantener la base de datos en diferentes lugares y siempre disponible.
- Replicación: existen dos tipos de replicación SQL y SAN. Replicación SAN (Red de Área de Almacenamiento) es simplemente mover datos de un punto A a un punto B. Replicación SQL en esta hay tres tipos de replicación:
- Replicación transaccional: es cuando en la base de datos se hace una transacción y se hace un commit a la base de datos. Los cambios se verán reflejados en segundos. Es mas usada cuando el DBMS tiene un alto volumen de transacciones.
- Replicación unida: es la replicación mas complicada ya que realiza los cambios concurrentes en ambas bases de datos, al realizar esto puede dar conflictos al tratar de sobrescribir y leer al mismo tiempo un dato.
- Replicación por Snapshot: es más comúnmente usada cuando los datos no se modifican muy seguidos ya que esta toma una copia instantánea de la base de datos y la sobrescribe.
- Reflejo de la base de datos: es una sincronización en tiempo real de los datos, con un failover más veloz que el cluster y log shipping. La única desventaja de esta tecnología es que solo permite el reflejo una vez por tanto no puede tener varias instancias.
Seguridad
Al tener la base de datos diseñada e implementada, programadores y usuarios necesitaran accesos para modificar los datos en la base de datos. Pero solo usuarios autenticados deben tener acceso para prevenir violaciones de seguridad. Es una responsabilidad del DBA asegurar que los datos solo estén disponibles para usuarios autorizados.
La seguridad debe ser administrada para varias acciones requeridas en el ambiente de la base de datos, como crear objetos en la base de datos, alterar la estructura de la base de datos, leer o modificar los datos en las tablas, modificar o configurar parámetros o especificaciones en el DBMS, entre otros. El DBA debe entender todos los aspectos de seguridad que impactan el acceso a la base de datos.
Muchas organizaciones toman acciones para ensamblar pólizas y procesos centralizadamente en un grupo de seguridad. Todo personal que maneje la base de datos debe ser entrenada a seguir estos procesos.
Asegurar la conformidad de las industrias y regulaciones gubernamentales es una tarea requerida en la administración de la base de datos, en lo que conforma implementar los controles necesarios. Es por lo que muchas empresas se centran en tener conformidad con regulaciones internacionales como son los ISO.
Una organización debe determinar y proveer los recursos necesarios para establecer, implementar, mantener y continuar con las mejoras a los sistemas de administración de la seguridad de la información. (ISO/IEC, 2019)
Como la última edición del ISO 27001:2013 establece haciendo auditorías internas, así como externas.
Backup y recuperación
El DBA debe estar preparado para recuperar todos los datos en caso de un problema. Por problema nos referimos a cualquier falla del sistema o error en el programa hasta un desastre natural. Las recuperaciones más comunes son resultado de algún error en la aplicación o error humano. El DBA debe estar preparado para recuperar los datos a un punto donde los datos sean útiles, sin importar el caso, y con la mayor brevedad posible. Existen tres tipos de recuperación de datos: recuperación corriente, recuperación de punto en el tiempo y la recuperación de transacciones. El DBA debe estar preparado para aplicar cualquier tipo de estas recuperaciones eso significa que debe desarrollar una estrategia de backup para asegurar que los datos no se pierdan.
Asegurar la integridad de los datos
El DBA debe diseñar la base de datos para que pueda almacenar los datos correctos en la correcta manera sin que los datos se dañen o se corrompan. Para asegurar este proceso el DBA debe implementar reglas de integridad usando características del DBMS. Existen tres aspectos de integridad relevantes para las bases de datos: físico, semántico, e interno.
Problemas físicos pueden ser manejados por características del DBMS como dominios y tipos de datos. También el uso de restricciones que pueden ser referenciales, únicas y de chequeo.
Integridad semántica es más difícil de controlar y con menos facilidad de definir. Pueden ser calidad de datos ingresados o redundancia de datos.
Por último, tenemos la integridad interna del DBMS. En la mayoría de los casos el DBMS mantiene una buena estructura, pero el DBA debe estar consciente como acoplar los datos en fallas internas del DBMS como:
- Consistencia de los índices: los índices funcionan para llevar una lista de punteros a los datos en las tablas de la base de datos. Si por alguna razón un índice pierde la sincronía de los datos, el acceso indexado puede fallar al devolver las consultas con los datos erróneos.
- Consistencia de punteros: a veces archivos muy grandes no están almacenados en el mismo lugar físico que otros datos. Por eso, el DBMS requiere una estructura de punteros para mantener los datos multimedia sincronizados con los datos de la tabla base.
- Consistencia de backup: A veces algunos DBMS toman un backup erróneo que efectivamente no se puede usar para la recuperación de los datos.
Asegurar la integridad de los datos es una habilidad necesaria en el rol de un DBA.
Ya descrito el rol de un DBA debemos enfocarnos en las algunas arquitecturas importantes en la base de datos, por medio de las cuales podemos tomar reseña según el uso que le daremos, estas tienen un rol especifico en una entidad, algunas se utilizan para el análisis de datos, y pues otras simplemente para almacenar datos.
ARQUITECTURA DE BASES DE DATOS
La arquitectura de computadoras se refiere a los atributos de un sistema que son visibles a un programador, o para decirlo de otra manera, aquellos atributos que tienen un impacto directo en la ejecución lógica de un programa. La organización de computadores se refiere a unidades funcionales y sus interconexiones, que dan lugar a especificaciones arquitectónicas.
Entre los ejemplos de atributos arquitectónicos se encuentran el conjunto de instrucciones, el número de bits usados para representar varios tipos de datos (por ejemplo: números, caracteres), mecanismo de E/S y técnicas para direccionamiento de memoria. Entre los atributos de organización se incluyen aquellos detalles de hardware transparente para el programador, tales como señales de control, interfaces entre el computador y los periféricos y la tecnología de memoria usada.
(William Stallings,2005) “Históricamente, y aún hoy en día, la distinción entre arquitectura y organización ha sido importante. Muchos fabricantes de computadores ofrecen una familia de modelos, todos con la misma arquitectura, pero con diferencias en la organización”.
Consecuentemente los diferentes modelos de la familia tienen precios y prestaciones distintas. Más aún, una arquitectura puede sobrevivir muchos años, pero su organización cambia con la evolución de tecnología. Un ejemplo destacado de ambos fenómenos es la arquitectura IBM Sistema/370. Esta arquitectura apareció por primera vez en 1970 e incluía varios modelos. Un cliente con necesidades modestas podía comprar un modelo más barato y lento, y, si la demanda se incrementaba, cambiarse más tarde a un modelo más caro y rápido sin tener que abandonar el software que ya se había desarrollado. Podemos destacar que la arquitectura del Sistema/370 con unas pocas mejoras ha sobrevivido hasta hoy día como la arquitectura de la línea de grandes productos de computación IBM
Hay tres características importantes inherentes a los sistemas de bases de datos: la separación entre los programas de aplicación y los datos, el manejo de múltiples vistas por parte de los usuarios y el uso de un catálogo para almacenar el esquema de la base de datos.
El objetivo de la arquitectura de tres niveles es el de separar los programas de aplicación de la base de datos física.
- En el nivel interno se describe la estructura física de la base de datos mediante un esquema interno. Este esquema se especifica mediante un modelo físico y describe todos los detalles para el almacenamiento de la base de datos, así como de los métodos de acceso.
- En el nivel conceptual se describe la estructura de toda la base de datos para una comunidad de usuarios (todos los de una empresa u organización), mediante un esquema conceptual. Este esquema oculta los detalles de las estructuras de almacenamiento y se concentra en describir entidades, atributos, relaciones, operaciones de los usuarios y restricciones. En este nivel se puede utilizar un modelo conceptual o un modelo lógico para especificar el esquema.
- En el nivel externo se describen varios esquemas externos o vistas de usuario. Cada esquema externo describe la parte de las bases de datos que interesa a un grupo de usuarios determinados y ocultos a ese grupo el resto de la base de datos.
La mayoría de los SGBD no distinguen del todo los tres niveles. Algunos incluyen detalles del nivel físico en el esquema conceptual. En casi todos los SGBD que se manejan vista de usuario, los esquemas externos se especifican con el mismo modelo de datosque describe la información a nivel conceptual, aunque en algunos se puede utilizar diferentes modelos de datos en los niveles conceptuales y externos.
En un SGBD basado en la arquitectura de tres niveles, cada grupo de usuarios hace referencia exclusivamente a su propio esquema externo. Por lo tanto, el SGBD debe transformar cualquier petición expresada en términos de un esquema externo a una petición expresada en términos del esquema conceptual, y luego, a una petición en el esquema interno, que se procesará sobre la base de datos almacenada. Si la petición es de una obtención (consulta) de datos, será preciso modificar el formato de la información extraída de la base de datos almacenada, para que coincida con la vista externa del usuario. El proceso de transformar peticiones y resultados de un nivel a otro se denomina correspondencia o transformación. Estas correspondencias pueden requerir bastante tiempo, por lo que algunos SGBD no cuentan con vistas externas.
(Alfonzo Aníbal,2018) “La arquitectura determina como la estructura física soporta la tecnología de información de la organización. Esto hace que sea fundamental, para el análisis, diseño y la división jerárquica en subsistemas interrelacionados, cada uno de estos se desarrolla en estructuras hasta alcanzar el nivel más bajo o elemental”.
La arquitectura de la información es importante para determinar la estructura coherente de módulos que soportan la tecnología de información en la organización. Recuerde que de cada nivel es importante el funcionamiento y la estructura. Tal como se referencia en la figura 1:

Figura 1
Funcionamiento.
Tanto la estructura como el funcionamiento de un computador son en esencia sencillos. La figura anterior señala las funciones básicas que un computador puede llevar a cabo. En términos generales hay solo cuatro:
- Procesamiento de datos.
- Almacenamiento de datos.
- Transferencias de datos
- Control
El computador, por supuesto, tiene que ser capaz de procesar datos. Los datos pueden adoptar una gran variedad de formas, y el rango de los requisitos de procesado es amplio. También es esencial que un computador almacene datos, incluso si el computador está procesando datos al vuelo (es decir, los datos se introducen, se procesan, y los resultados se obtienen inmediatamente), el computador tiene que guardar temporalmente al menos aquellos datos con los que está trabajando en un momento dado. Así hay al menos una función de almacenamiento de datos a corto plazo. Con igual importancia el computador lleva a cabo una función de almacenamiento de datos a largo plazo. El computador almacena ficheros de datos para que se recuperen y actualicen en un futuro.
El computador tiene que ser capaz de transferir datos entre él mismo y el mundo exterior. El entorno de operación del computador se compone de dispositivos que sirven bien como fuente o bien como destino de datos. Cuando se reciben o se llevan datos de un dispositivo que está directamente conectado con el computador, el proceso se conoce como entrada-salida (E/S), y este dispositivo recibe el nombre de periférico. El proceso de transferir datos a largas distancias, desde o hacia un dispositivo remoto, recibe el nombre de comunicación de datos.
Finalmente, debe haber un control de estas tres funciones. Este control es ejercido por el (los) ente(s) que proporcionan(n) al computador instrucciones. Dentro del computador, una unidad de control gestiona los recursos del computador y dirige las prestaciones de sus partes funcionales en respuesta a estas instrucciones.
(William Stallings, 2005) “Hay, sorprendentemente, muy pocas formas de estructuras de computadores que se ajusten a la función que va ser llevada a cabo. En la raíz de esto subyace el problema de la naturaleza de uso general de los computadores, en la cual toda la especialización funcional se tiene cuando se programa y no cuando se diseña”
En la figura 2 se muestra el sistema para el acceso físico a la base de datos. Se puede ver la interacción del usuario con el sistema de bases de datos al iniciar una consulta. El selector de estrategia traduce la orden del usuario a su forma más eficiente para su ejecución. La orden traducida activa entonces al administrador de buffer, que controla el movimiento de datos entre la memoria principal y el almacenamiento en disco. El administrador de archivos da soporte al administrador de buffer administrando la reserva de localizaciones de almacenamiento en disco y las estructuras de datos asociadas. Además de los datos del usuario, el disco contiene el diccionario de datos, que define la estructura de los datos del usuario y como estos pueden usarse.
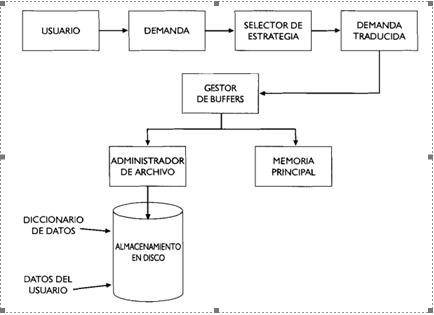
Figura 2
(Gary W. Hansen, James V. Hansen ,2018)“La memoria principal es el almacenamiento intermedio usado por los datos que están disponibles para las operaciones del usuario. Aquí es donde reside la ejecución del programa”
Como los datos se necesitan por el programa para ejecutar sus funciones, se transmiten desde el almacenamiento secundario a la memoria principal. Aunque la memoria principal puede ser capaz de almacenar varios megabytes de datos, es normalmente muy pequeña para almacenar la base de datos completa, por lo que es necesario el almacenamiento secundario.
Los datos del usuario se almacenan como una base de datos físicas o colección de registros. Por ejemplo, una fila en una tabla puede almacenarse como un registro físico, donde cada valor de los atributos de la fila se almacena en su propio campo. Análogamente, un registro lógico de un modelo en red o jerárquico puede almacenarse como un registro físico donde los elementos de datos lógicos se convierten en elementos de datos físicos del registro físico almacenado.
El almacenamiento secundario para los sistemas de bases de datos está compuesto generalmente por el almacenamiento en disco y el almacenamiento en cinta magnética. Casi siempre, la base de datos completa se almacena en disco y porciones de ésta se transfiere desde el disco a la memoria primaria, a medida que se necesita. El almacenamiento en disco es la forma principal de almacenamiento con acceso directo, por lo que los registros individuales se pueden acceder directamente. Aunque el almacenamiento en cinta magnética es menos costoso que el almacenamiento en disco, los registros pueden ser solamente accedidos secuencialmente (y más lentamente que en disco). Su función en el sistema de bases de datos está básicamente limitada archivar datos.
Arquitectura Big Data
Según (Joyanes Aguilar, 2013) “las arquitecturas Big Data deben implementar las nuevas tecnologías de volúmenes de datos y la integración de datos tradicionales”, recordemos que esta arquitectura se usa para grandes combinaciones de datos que no pueden manejarse con facilidad ,sino por medio de estadística y otros métodos matemáticos ,las empresas deben actuar rápido ya que a medida crece Big Data surgen nuevos métodos y tecnologías por implementar ,en base de datos administramos 3 tipos de datos fundamentales ,estos se dividen en 3 :
- Estructurados (Datos transaccionales de la base de datos)
- No Estructurados (audio, texto, video etc.)
- Semiestructurados (datos que proceden de archivos HTML y XML)
En la actualidad un Analista de Datos tiene como reto manejar todos estos tipos de datos, la arquitectura Big Data tiene un gran auge por ello este debe gestionar plataformas que ayuden al cuidado de estos datos, y así tener un rendimiento considerable.
El aumento considerable de Big Data según (Joyanes Aguilar, 2013) “Se debe a 4 pilares fundamentales en la actualidad que son medio sociales, la portabilidad, el internet de las cosas y la computación en la nube” ,estos pilares hoy en día tiene un avance enorme podemos considerar la computación en la nube como una necesidad de hacer respaldos de datos sin preocuparnos a perder un equipo físico o que este mismo se nos dañe, hoy en día distintas compañías nos brindan servicios en la nube seguros y con buen rendimiento ,algunas de estas empresas ya conocidas como Microsoft, Google ,Amazon etc., ofrecen estos servicios tanto para empresas como usuarios comunes.
En cuanto al internet de las cosas y la portabilidad recordemos que, al aumentar los servicios móviles, esto requiere aun un mayor manejo de datos por la empresa, de ahí el surgimiento del internet de las cosas donde podemos manipular distintos aparatos a través de sensores manejados a través de alguna aplicación con nuestros datos.
Los medios sociales forman finalmente uno de los almacenes de datos más enormes en la actualidad, ya que se recopilan cada día millones de datos a través de plataformas como Facebook, Twitter, LinkedIn, Instagram etc.
Estas a su vez tienen miles de analistas por medio de los cuales realizan estudios para brindar productos a sus usuarios que deseen comprar un producto mencionado por ellos, o simplemente conectarlos con personas que hace tiempo no habían visto, cuesta imaginar cómo será el trato de esta gran cantidad de datos, pero Big Data nos ayuda a realizar de una manera más optima y funcional esta administración de datos.
Al hablar de Big Data podemos mencionar 5 características fundamentales:
- Volumen
- Velocidad
- Variedad
- Veracidad
- Valor
El volumen (Joyanes Aguilar, 2013) “Entre 2015 a 2020 se espera que entremos a la era del zettabyte(1024 exabytes) ya que las grandes cantidades de datos que se producen cada día aumenten hasta llegar a estos rangos de volúmenes de datos”, la necesidad de las grandes compañías por aumentar sus ganancias, y permanecer en la lucha con las demás compañías competidoras ,hacen que el volumen de datos cada día crezca más y más en cuestión de ganar por medio de la publicidad brindada a través de diversas plataformas.
Al referirnos a velocidad nos basamos en el concepto de optimizar el control de los datos para la toma de decisiones en las compañías, y al referirnos en variedad recordemos que antes hablábamos de los tipos de datos (estructurados, no estructurados, semiestructurados) las bases de datos cuentan con todo tipo de datos y por medio de Big Data nos permite hacer análisis más concretos sobre todo tipo de datos, con números inmensos de datos.
Por último, haremos énfasis en el valor, sabemos que los datos que tienen las bases de datos son valiosos para las compañías, Big Data nos permite salva guardar esta información, como menciona (Joyanes Aguilar, 2013)” herramientas como Apache Hadoop es una herramienta muy económica que procesa grandes cantidades de datos a través cantidades de un clúster de grandes cantidades de computadoras” esta es una herramienta muy popular en esta área.
En resumen, vemos que este tipo de arquitectura es fundamental para empresas que administras millones, billones y hasta trillones de datos, que ocupan métodos estadísticos, y herramientas que requieren grandes costos para poder mantener funcionalmente toda esta arquitectura de almacenamiento de datos.
CONCLUSIONES
Podemos concluir que la infraestructura de base de datos a nivel empresarial depende del presupuesto y de la necesidad que una empresa tenga, consideramos que existen diferentes formas de almacenar data, hoy en día muchas empresas consideran el uso de almacenamiento de sus bases de datos en la nube, otras aun son capaces de tener su infraestructura física.
Un buen DBA aprende a conocer cada debilidad, fortaleza de su infraestructura, además de ello debe proponer mejorar de infraestructura, sobre todo como evitar desastres tanto a nivel de seguridad, como de ingenuidad de futuros empleados.
Las empresas actualmente solo usan bases de datos relacionales hoy en día pues el temor de no usar tecnologías no relaciones surge por el temor a lo desconocido y el amor a lo ya confiable, pero quien sabe y en un futuro el mercado se llene de bases de datos no relacionales que poco a poco van introduciéndose en el campo de base de datos como Mongo DB ,por ahora solo podemos decir que este dominio de bases de datos relaciones lo mantiene las bases de datos Oracle Y SQL Server .
Referencias
- Marqués, A. M. (2011). Bases de Datos. Castellón de la Plana: Universidad Jaume I.
- Capacho, J. R., Bernal, W., & Nieto Bernal, W. (2017). Diseño de bases de datos. Universidad del Norte.
- Castro Romero, A., González Sanabria, J. S., & Callejas Cuervo, M. (2012, 12 diciembre). Utilidad y funcionamiento de las bases de datos NoSQL. Sistema de Información Científica Red de Revistas Científicas de América Latina, el Caribe, España y Portugal, 24(38). https://www.redalyc.org/pdf/4139/413940772003.pdf
- L. (2018, 31 mayo). Windows Server – Win32 apps. Microsoft Docs.https://docs.microsoft.com/en-us/windows/win32/srvnodes/windows-server#:%7E:text=Windows%20Server%20is%20a%20group%20of%20operating%20systems,networking,%20and%20various%20improvements%20to%20the%20file%20system
- Server – for scale out workloads. (2020). Ubuntu. https://ubuntu.com/server
- Gómez, J. M. P., & PIÑEIRO GOMEZ, J. M. (2014). UF2175 – Diseño de bases de datos relacionales. El Cid Editor.
- Wendy A. Neu, Vlad Vlasceanu, Andy Oram y Sam Alapati, (Septiembre,2019), Una introducción a las bases de datos en la nube, 1er Edición.
- Mullins, C., (2013). Database Administration The Complete Guide to DBA Practices and Procedures [Administración de Base de Datos La Guía Completa para las Practicas y Procedimientos de un DBA], Old Tappan, New Jersey: Pearson Education, Inc.
- William Stallings, 2005 “Organización y arquitectura de computadores” séptima edición, PEARSON EDUCACION, S.A., Madrid
- Alfonzo Aníbal Guijarros Rodríguez, Pedro Manuel García Arias, Ángela Olivia Yanza Montalván, (2018,) “Organización y arquitectura computacional. Un enfoque práctico”, editorial académica universitaria.
- Gary W. Hansen, James V. Hansen, (1997), “Diseño y Administración de Bases de Datos” segunda edición,PRENTICE HALL.
- Joyanes Aguilar, L., 2013. Big data. 1st ed. México: Alfaomega.
